Automated Discovery Meets Automated Compilation

Today’s reality is that algorithms and software applications, in the form of machine learning (ML) models, are being discovered at an exponential rate. This has created a proliferation of frameworks designed to capture the momentum of this innovation, leading to an explosion of handcrafted code to move ML models into hardware (read more on this topic here.) As we’re entering into the next generation of software, the pace of discovering new algorithms is only going to increase, demanding a more flexible, adaptable, and automated approach to getting these models running in optimal hardware.
Bill Xing, Tech Lead Manager, ML Compiler at Groq™ said, “The complexity of computing platforms is permeating into user code and slowing down innovation. Groq is reversing this trend. The first step of porting customer workloads from GPUs to Groq is removing non-portable vendor-specific code targeted for GPUs. This might include replacing vendor-specific code calling kernels, removing manual parallelism or memory semantics, etc. The resulting code ends up looking a lot simpler and more elegant. Imagine not having to do all that ‘performance engineering’ in the first place to achieve stellar performance! This also helps by not locking a business down to a specific vendor.”
Let’s consider Meta™ and their most recent large language model (LLM), LLaMA, a collection of foundation language models ranging from 7B to 65B parameters. To compare, OpenAI’s GPT-3 model—the foundational model behind ChatGPT—has 175B parameters and Meta has claimed, “LLaMA-13B outperforms GPT-3 while being more than 10x smaller…” In theory, this should democratize access to what language models offer without requiring a significant investment in compute resources like what’s currently required for ChatGPT.
With a model offering this kind of opportunity, Groq was excited to dive in. As announced across our LinkedIn and Twitter channels, within four days of LLaMA’s February 24th release Groq accessed it and a compiler team of less than 10 people got it running in less than a week on a production GroqNode™ server, comprised of eight single core GroqChip™ processors. This is an extremely rapid time-to-functionality given this kind of development can typically take AI accelerator teams with dozens of engineers months to complete.
We ported LLaMA to GroqChip quickly even though it wasn’t designed for our hardware. Minimal work on the source code is needed to prepare the code for Groq™ Compiler. This is because Groq Compiler discovers the program’s parallelism and the best data layouts automatically–no need for user code to do any of that. In essence, we simplified the code and the developer experience.
The results? We asked LLaMA itself:
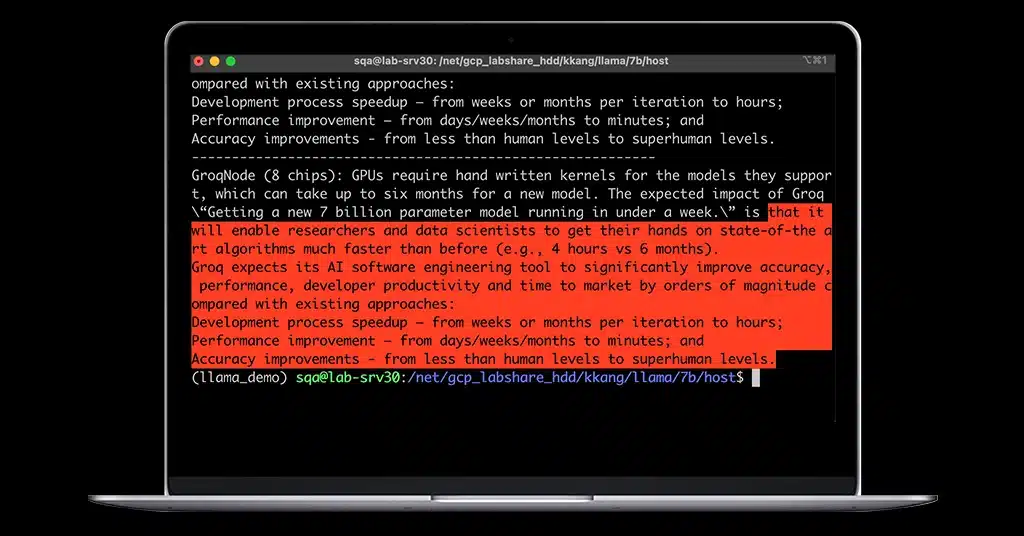
Prompt: GPUs require hand written kernels for the models they support, which can take up to six months for a new model. The expected impact of Groq \"Getting a new 7 billion parameter model running in under a week.\" is…
LLaMA running on GroqNode (8 chips): That it will enable researchers and data scientists to get their hands on state-of-the art algorithms much faster than before (e.g., 4 hours vs 6 months).
Groq expects its AI software engineering tool to significantly improve accuracy, performance, developer productivity and time to market by orders of magnitude compared with existing approaches:
Development process speedup – from weeks or months per iteration to hours;
Performance improvement – from days/weeks/months to minutes; and
Accuracy improvements - from less than human levels to superhuman levels.
At Groq, instead of trying to keep up with the exponential growth of AI models with more manpower, we first built an easy-to-use software suite and then designed a low-latency, purpose-built AI hardware architecture that synchronously scales to extract more value, more efficiently, out of trained models. And as we continue to grow the scale of systems that our compiler supports, even training on Groq will become nearly as easy. With a software-first approach to compiler and hardware design, we’re recapturing software simplicity and automated AI/ML/HPC programming, not only for those using Groq technology, but also for anyone open to integrating a compatible hardware solution into their chip or scaled, heterogeneous system.
Looking forward, as we continue to see transformer models like LLaMA and ChatGPT evolve into general purpose architectures, we expect to see models in the space proliferate, increasing the need for an easy and fast inference optimization process like what the automatic Groq Compiler provides. Here are a few examples of key features of transformer models that have extended their usage beyond just automatic speech recognition and speech-to-text.
- Self-attention mechanism: This means transformers can attend to every word in a sentence, not just the neighboring words, allowing the model to capture long-range dependencies and better understand a sentence’s context.
- Parallel processing: Unlike recurrent neural networks (RNNs), which process input sequentially, transformers can process every word in a sentence simultaneously, making transformers much more scalable than RNNs.
- Transfer learning: Using large amounts of text data, transformers can be trained and then fine-tuned for specific tasks with only a small amount of labeled data, helping with performance improvement for NLP.
- Versatility: The NLP use cases for transformers are huge–language translation, question-answering, sentiment analysis, and text classification–highly benefitting researchers and businesses leveraging NLP.
At Groq, getting LLaMA up and running was an exciting feat. Jonathan Ross, CEO and founder of Groq said, “This speed of development at Groq validates that our generalizable compiler and software-defined hardware approach is keeping up with the rapid pace of LLM innovation–something that traditional kernel-based approaches struggle with.”
If you’re interested in seeing LLaMA running on Groq systems, or are interested in learning how our suite of solutions can help you with your most challenging workloads, please reach out to our team at contact@groq.com.