Meet Groq™ Compiler
The compute industry has a problem. Accelerating architectural complexity (multi-core, etc.) has shifted the burden of managing that complexity over to software developers, creating an explosion of frameworks, programming models, and libraries, particularly where the functionality of each methodology or framework overlaps with those of others. This explosion of complexity for the software developer begs the question, “What’s the right framework for me?” Below is just a subsample of what’s out there (with more emerging every month), bombarding the developer and hungry for attention.

Realistically, in PyTorch for example, a developer can express the vast majority of high performance computing (HPC) and machine learning (ML) workloads. So why are there hundreds of different programming variants tackling the same issue?
Diving deeper into a single framework–again, take PyTorch for example–there is this explosion of functionality within it, or what we at Groq refer to as the explosion of kernels. A simple example can be found in convolutions. There are almost 70 variants of how to do convolutions within PyTorch with strong overlap in terms of the functionality of these operators. In some cases, they are functionally equivalent, but different implementations are required for different hardware targets.
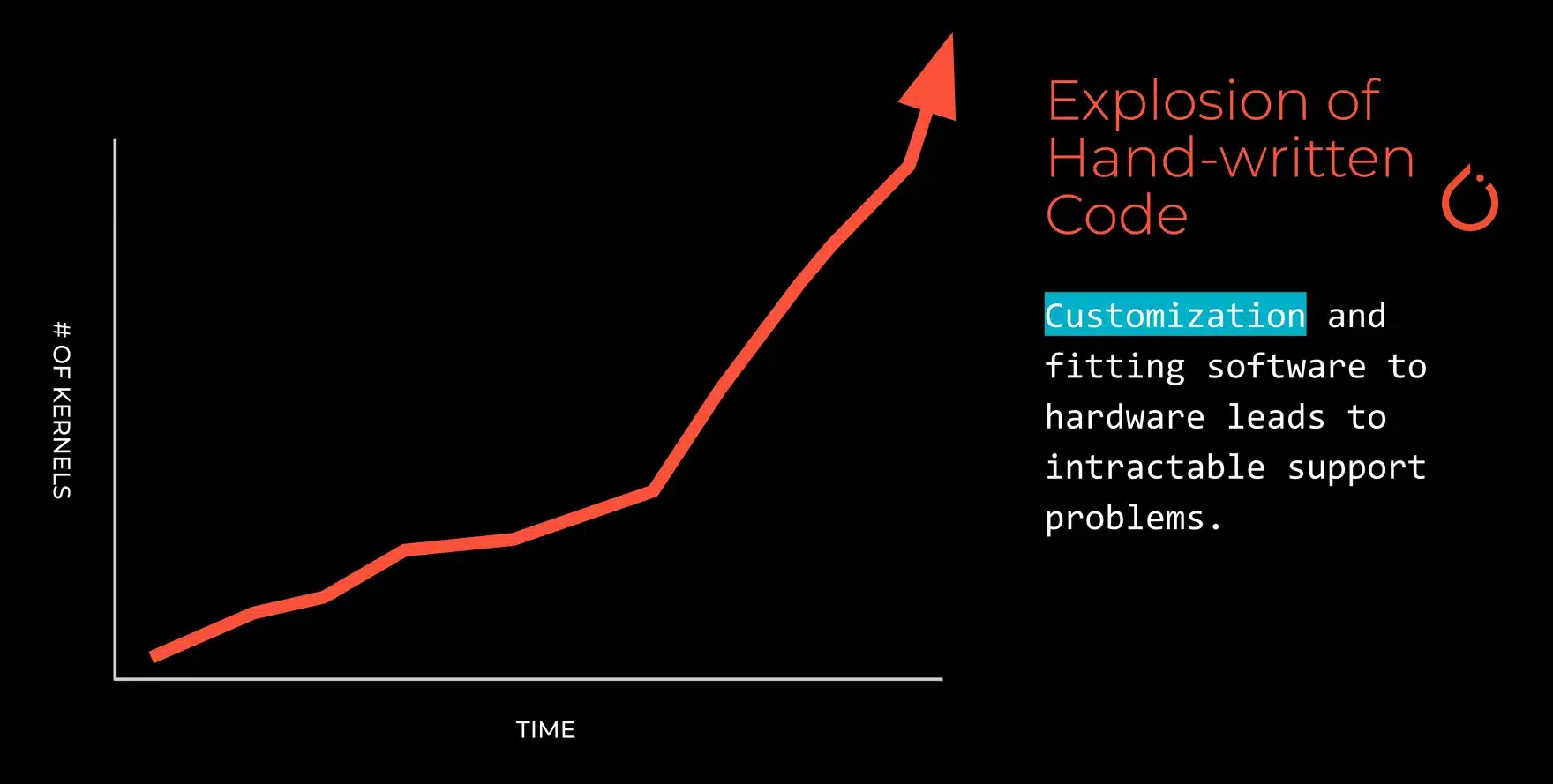
This is just one symptom of a deeper problem where the backend hardware and its complexity are breaking through the higher level abstractions and leading to orders of magnitude more complexity for the end developer. The crux of the problem isn’t so much the frameworks themselves; those are really just a response to the need for customization that’s required at the software layer. The bigger problem is that breaking abstractions for the developer makes it harder and more complex to develop new applications. The result? An intractable support problem, both for these various software stacks and for building applications.
Because Groq, a company driving the cost of (both developing and deploying) compute to zero, focused on the software and developer experience first, we came up with a simplistic way to compile Deep Learning and HPC models. From there we devised a deterministic hardware architecture that led to a much simpler software stack and compilation flow.
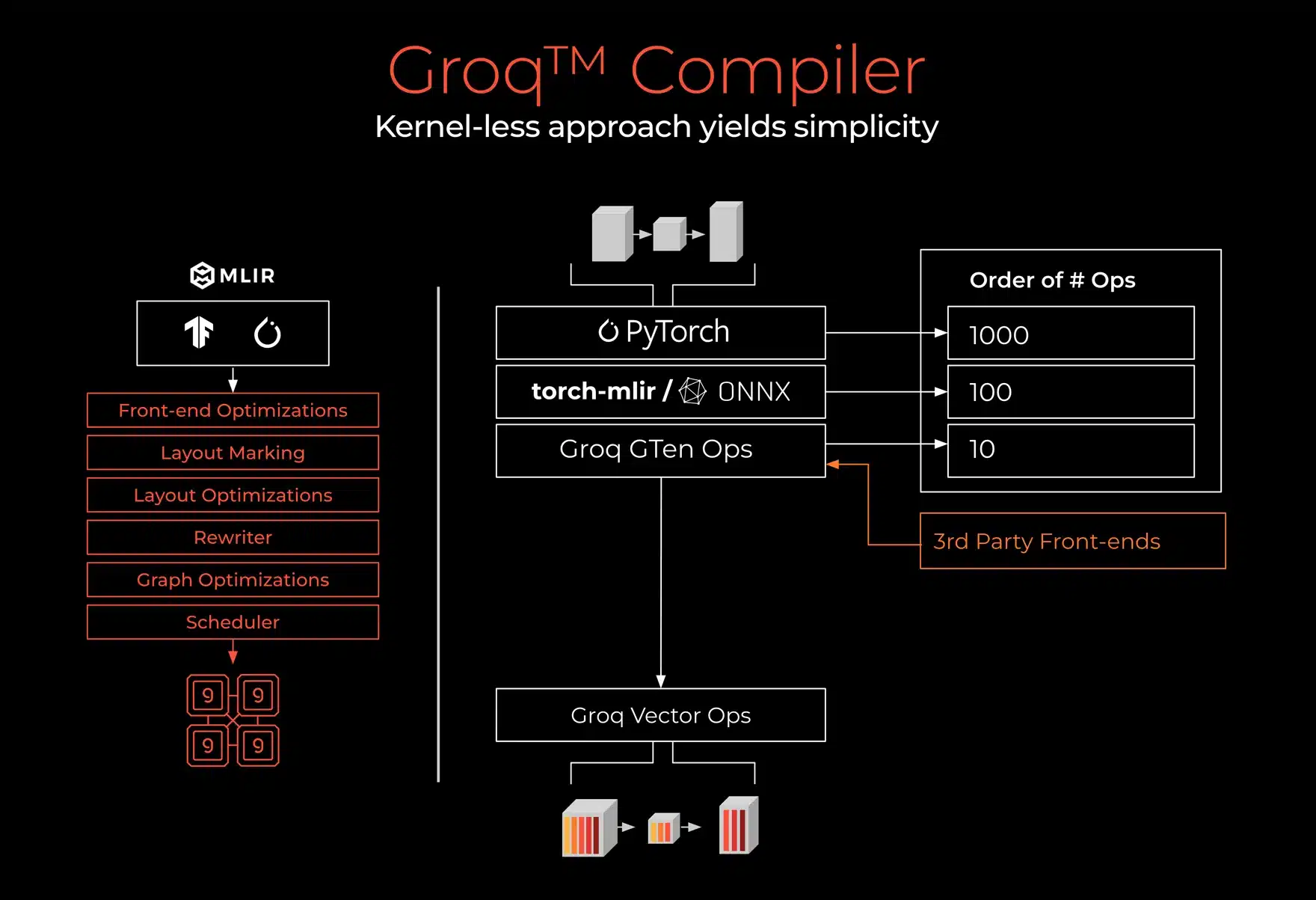
Referencing the image above, on the left is a simple illustration of the overall Groq compilation flow where the user:
- Takes high level models from TensorFlow or PyTorch
- Does front-end optimizations
- Performs layout markings and optimizations–taking multidimensional tensors and maps them down to our physical address space which is relatively simple and one dimensional as it doesn’t have hierarchy
- Re-writes, taking higher level neural network graphs and decomposing of them into semantically equivalent graphs, but simpler in the sense that the operations within the graph are amenable to operations that exist on GroqChip™
- Lastly, does vector-level scheduling
As illustrated on the right hand side, uniquely, the number of functions or operations required at the Groq-specific layers to work performantly for the compiler is very small. You can think of them as simple functional buttons on a calculator. We take the PyTorch model, consisting of thousands of operations, and decompose it into torch-mlir or ONNX using a lot of open-source frameworks and tools. From that, we digest it and decompose it further into an even smaller subset, called Groq GTen ops, which is our dialect or operation set to support the vast array of Deep Learning and HPC workloads. Importantly, we are not using or creating custom kernels and custom optimizations, or custom fusing. Instead, we decompose the tens of Groq Gten ops automatically into simpler representations through Groq Compiler, then schedule them.
With this innovative approach, instead of trying to keep up with the exponential growth of AI models with more manpower, Groq first built an easy-to-use software suite and then designed a low-latency, purpose-built AI hardware architecture that synchronously scales to extract more value, more efficiently, out of trained models. And as we continue to grow the scale of systems that our compiler supports, even training on Groq will become nearly as easy. With a software-first approach to compiler and hardware design, we’ve recaptured software simplicity and automated AI/ML/HPC programming, not only for those using Groq technology, but also for anyone open to integrating a compatible hardware solution into their chip or scaled, heterogeneous system.
One primary impact of the Groq technology simplicity is the speed of execution by adding completeness and functionality to the compiler. By only needing to support a few ops, and not needing to manually develop kernels for each op and the particular context in which it’s being deployed, development speed is much faster. Many compilers fail in their generality, oftentimes, forcing developers to modify their workloads to the needs of the compiler. At Groq, we give the developer freedom to choose their own workloads. The impact of this is substantial; in just 45 days, we tripled the number of models we could feed into Groq™ Compiler by randomly harvesting the most popular models from the most used platforms. This level of code deployment on the leading legacy competitor’s development platform would have taken literally thousands of developer-years. We anticipate being able to continue this rate of improvement (we refer to the high standard of compiler flexibility as MLAgility). No other company, large or small, has been able to show this level of progress with their compiler technology. In the rapidly evolving space of Deep Learning and HPC, speed of development is critical to ensuring that tomorrow’s ideas aren’t stuck behind the labor-intensive ways of latency platforms.