
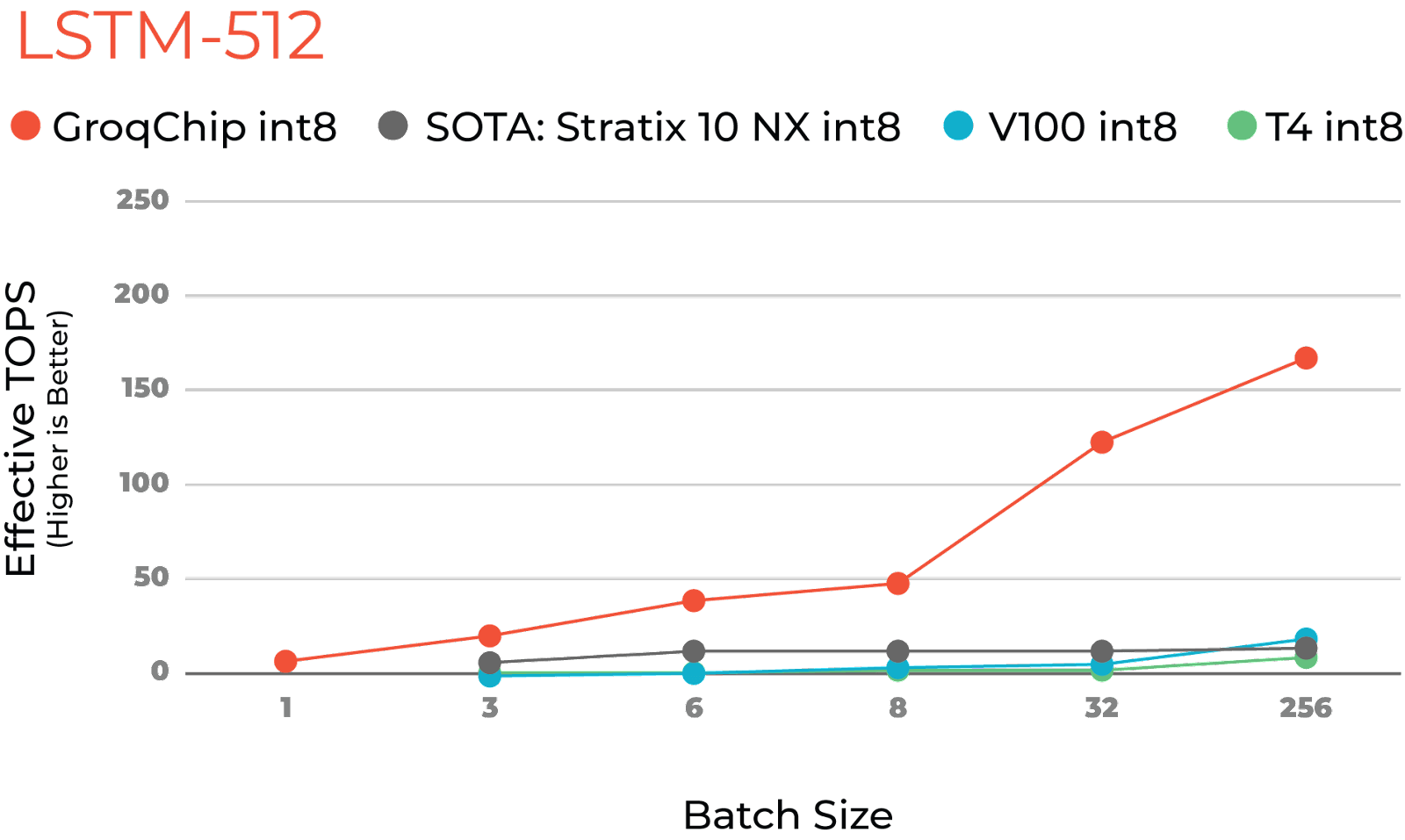
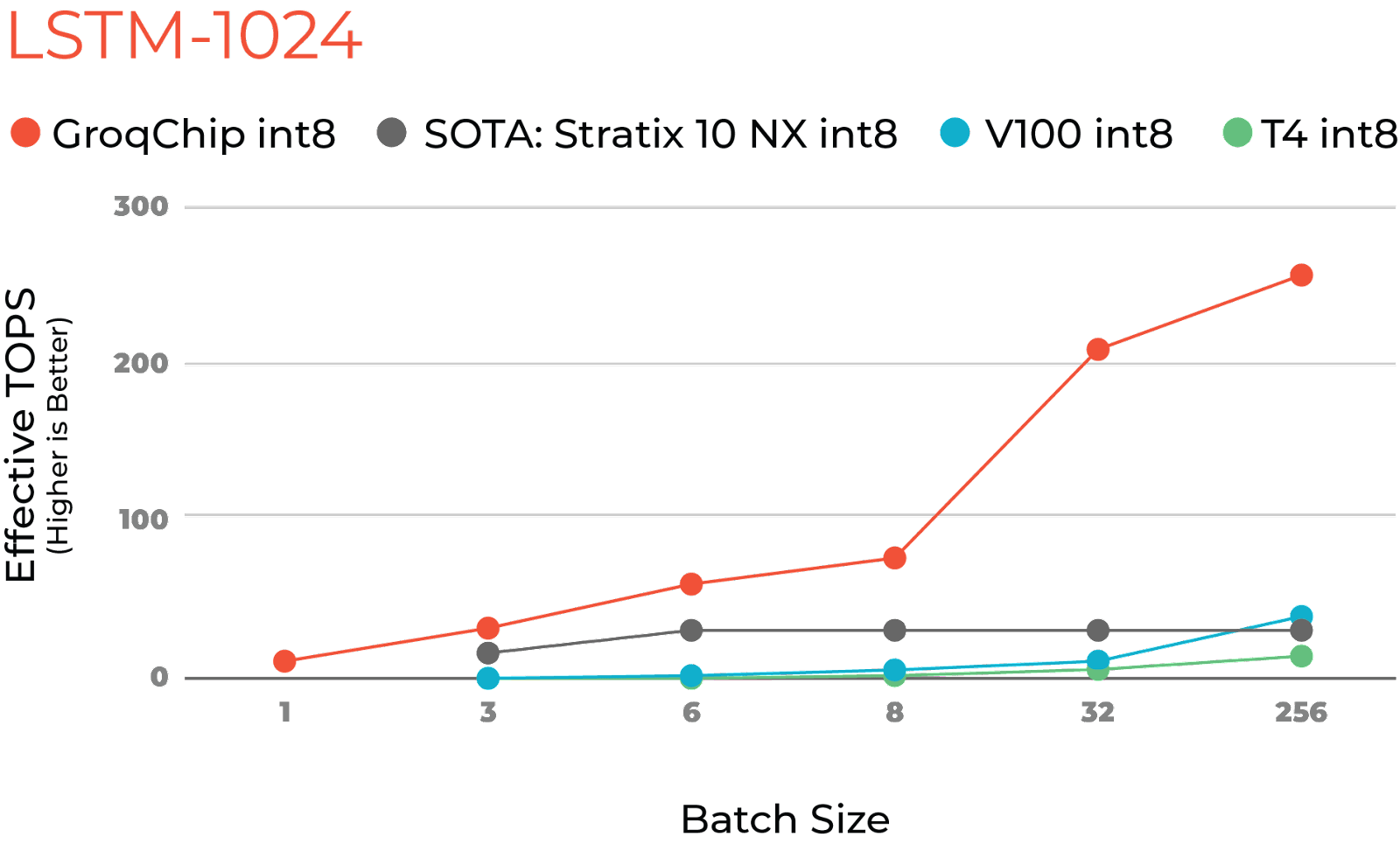
Figure 1 – Comparison of LSTM Performance Across Batch Sizes
The authors’ results show that their implementation on the Intel Stratix 10 NX FPGA significantly surpasses Nvidia V100 and T4 performance at small batch sizes, as shown by the grey, blue, and green lines in Figure 1, respectively. The FPGA shines in these latency-sensitive small-batch scenarios thanks to its balanced compute/memory/bandwidth and chaining capabilities. However, the paper also shows that increasing the batch size on GPU mitigates the GPU’s bottlenecks for throughput-bound scenarios.
The orange line in Figure 1 shows what I was able to accomplish in my first 2 weeks at Groq. GroqChip delivers the best of both worlds, exceeding NX performance at small batch sizes and GPU performance at larger batch sizes. All with a program written for our chip in less than 500 lines of well-commented code. Let’s drill into what makes this possible.
Compute Analysis
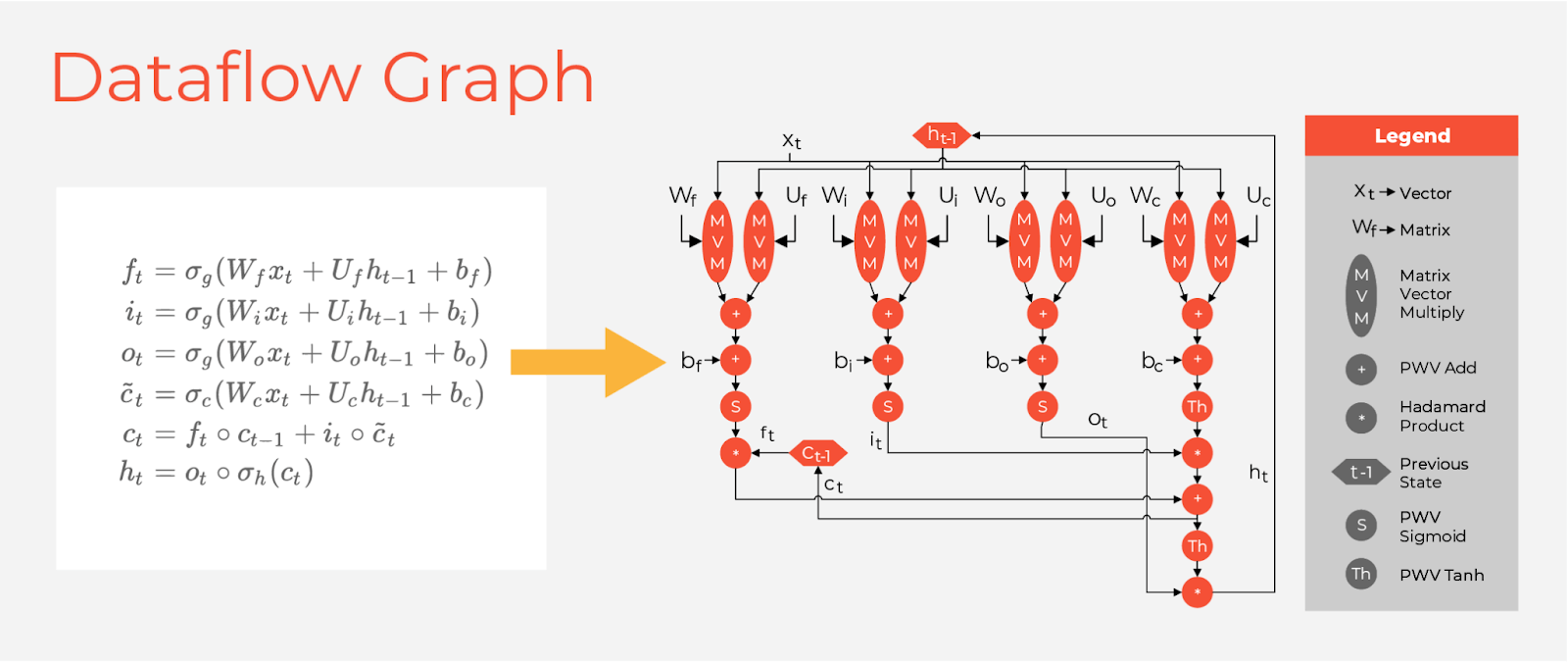
My first step in mapping the LSTM workflow to GroqChip was to analyze the LSTM’s compute graph. In Figure 2, we see the LSTM has eight matrix-vector multiplication ops upfront, followed by a sequence of pointwise vector operations that reduce to cell and hidden state vectors at the bottom. These state vectors are passed into the next time step of the LSTM, creating a loop-carried dependence between time steps.
Generally speaking, processors will struggle with two aspects of low-batch LSTMs. First, matrix-vector multiplications only involve two arithmetic operations for each byte of input data. LSTMs, and other algorithms characterized by this low ops:data ratio, will be bottlenecked on architectures that don’t have the memory bandwidth to keep up with high compute throughput. Likewise, an architecture can claim a balanced compute:bandwidth ratio if it can sustain high throughput on this kind of workload.
The second problem is the loop-carried dependence between LSTM time steps, which creates a critical path that can stall a processor until the results of the last few pointwise vector ops are made available to the next round of matrix-vector multiplication. The race to complete the pointwise operations can bottleneck processors even if they have strong matrix-vector multiply capabilities. Therefore, a balanced architecture for LSTMs must also have the right ratio of matrix:vector capabilities.
FPGAs have excelled at serving LSTMs in real time because they provide balanced compute:memory ratios for matrix-vector multiply and their reconfigurable logic facilitates deeply pipelined datapaths that race through the critical path and deliver balanced matrix:vector capabilities. As we’ll see in the rest of this article, GroqChip also has a balanced spatial architecture with comparable ratios and features that help it set state-of-the-art performance for low latency LSTM inference (i.e., low-batch or batch=1).
GPUs, on the other hand, are able to apply large batches to improve compute throughput. Generally speaking, inference batching is a technique that fuses many inputs together to optimize throughput, often at the cost of latency. Inference services must carefully consider this tradeoff on a per-application basis, often with the goal of maximizing throughput without exceeding a latency requirement.
In LSTMs, a primary benefit of batching is that a batched matrix-vector multiply is essentially a matrix-matrix multiply, which scales the op:data ratio by the batch size to improve compute utilization.
In the next section we discuss how GroqChip scales performance along the entire latency-throughput tradeoff space.
Source: https://www.microsoft.com/en-us/research/uploads/prod/2018/06/ISCA18-Brainwave-CameraReady.pdf
Figure 2 – LSTM Compute Graph
GroqChip™/LSTM Technology Mapping
The high level technology mapping of LSTMs onto GroqChip is shown in Figure 3. The two major classes of operations in the LSTM, matrix-vector multiplies and pointwise operations, map directly to the GroqChip matrix execution module (MXM) and vector execution module (VXM), respectively.
As discussed in the previous section, the matrix-vector multiplies require high memory bandwidth because they use one byte of data for every two int8 ops. My LSTM implementation for the GroqChip concurrently leverages 32 of the chip’s 88 total memory (MEM) slices to load matrix data (i.e., trained LSTM weights) into MXM for a total of 32 slices * 320 bytes/cycle * 1 GHz clock rate = 10 TB/s of effective memory bandwidth. Matrices are carried from MEM to MXM on 32 of the chip’s 64 available stream resources, providing plenty of on-chip communication bandwidth. Therefore, the maximum effective throughput on MXM of up to 10 TB/s * 2 ops/byte = 20 tera-ops/second (TOPS) at batch=1.
When we increase the batch size, GroqChip MXM provides hardware acceleration for matrix-matrix multiplication. For modest batch sizes, the additional inputs in the batch simply fill in spare cycles in the schedule between bursts of weight loading. We see this impact in Figure 1, where batch=8 scales the throughput of GroqChip by 7x at only a 20% cost to latency for LSTM-1024, relative to batch=1. Meanwhile, batch=256 leverages even more of the MXM’s resources to scale throughput by 23x.
Finally, we map the LSTM’s pointwise operations onto a sequence of 4 chained operations in the VXM, which executes the entire critical path loop-carried dependence in as little as 150 nanoseconds for a batch=1 LSTM-512. The VXM mapping also provides an advantage when the batch size is increased. Increasing the batch size from 1 to 8 for the LSTM-512 model accounts for an additional latency of only 56 nanoseconds.
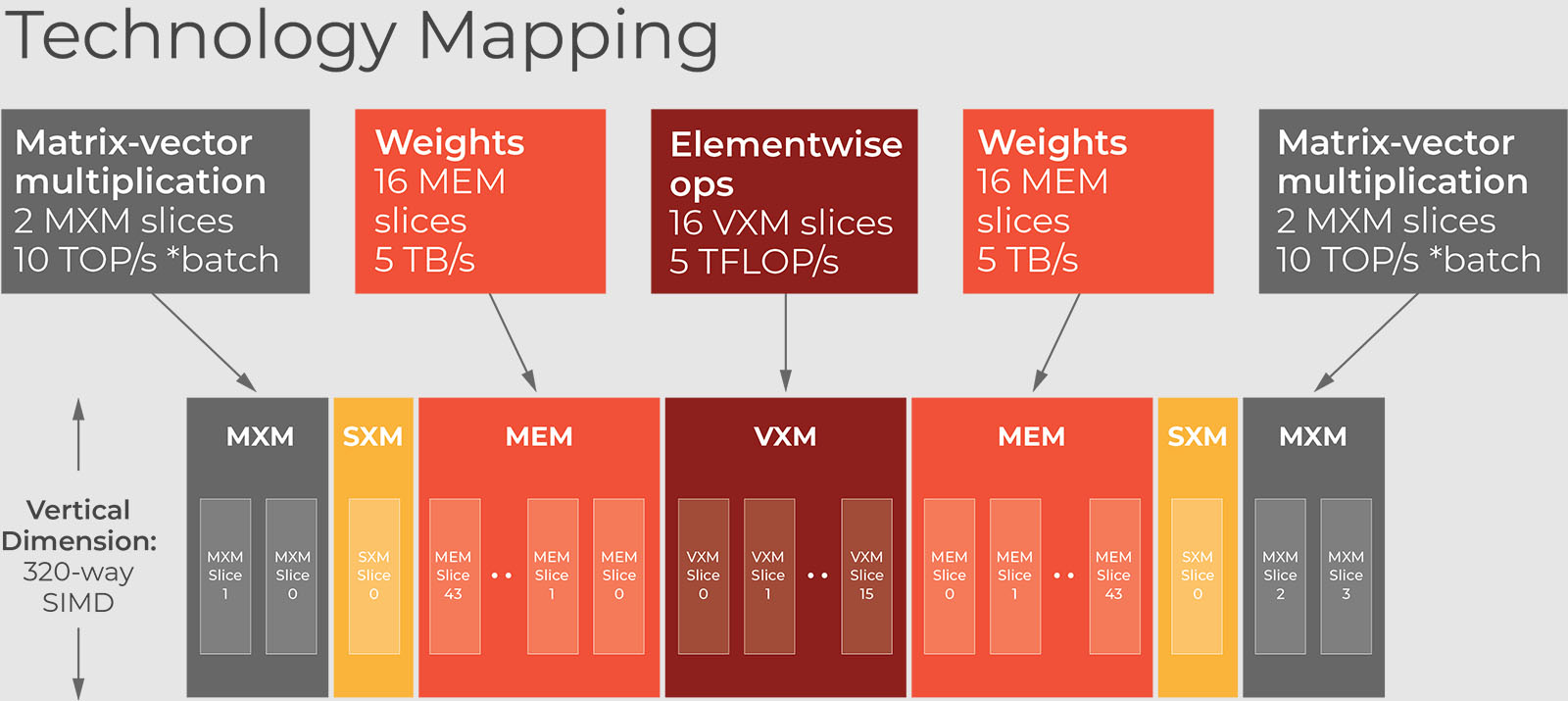
Figure 3 – High Level Technology Mapping of LSTMs onto GroqChip
Bottom Line
LSTM workloads are notoriously memory bandwidth bound, and GroqChip solves this with a ratio of compute to memory that is balanced for low-batch scenarios and scales to over 250 effective tera-ops/second in high-batch scenarios. LSTMs are also latency bound, limited on the ability to chew through pointwise operations. GroqChip handles this through its vector execution module and operation chaining feature.
GroqChip is the perfect match for LSTM because it combines these features with the right granularity of compute and tools to empower developers to rapidly capture the available performance.
I would love to go into the next level of detail for both the technology mapping and the tools that helped me get this implemented in only 2 weeks. Please reach out to me on LinkedIn and let me know what you would like to see in future content.
Jeremy Fowers works with Groq’s customers to accelerate the flywheel of customer solutions and Groq innovation. Previously, he was part of the Microsoft Catapult project and co-founded the Microsoft Brainwave project for hyperscale DNN acceleration on FPGAs. He earned his PhD in high performance reconfigurable computing on FPGAs at the University of Florida.
Want to Work with Jeremy? Click here to find your Groq Opportunity
Interested in Learning More?
For more information on Groq technology and products, contact us at info@groq.com, follow us on Twitter @GroqInc and connect with us on LinkedIn https://www.linkedin.com/company/groq.

References:
- A. Boutros et al., “Beyond Peak Performance: Comparing the Real Performance of AI-Optimized FPGAs and GPUs,” 2020 International Conference on Field-Programmable Technology (ICFPT), 2020, pp. 10-19, doi: 10.1109/ICFPT51103.2020.00011.
©2021 Groq, Inc. All rights reserved. Groq, the Groq logo, GroqChip, GroqWare, and other Groq marks are trademarks of Groq, Inc. Other names and brands may be claimed as the property of others.