
ArtificialAnalysis.ai Shares Gemma 7B Instruct API Providers Analysis, with Groq Offering Up To 15X Greater Throughput
In the world of large language models (LLMs), efficiency and inference speed are becoming increasingly important factors for real-world applications. That’s why the recent benchmark results by ArtificialAnalysis.ai for the Groq LPU™ Inference Engine running Gemma 7B are so noteworthy.
Gemma is a family of lightweight, state-of-the-art open-source models by Google DeepMind and other teams across Google, built from the same research and technology used to create the Gemini models. Notably, it is part of a new generation of open-source models from Google to “assist developers and researchers in building AI responsibly.”
Gemma 7B is a decoder-only transformer model with 7 billion parameters that, “surpasses significantly larger models on key benchmarks while adhering to our rigorous standards for safe and responsible outputs.” Specifically, Google:
- Used automated techniques to filter out certain personal information and other sensitive data from training sets
- Conducted extensive fine-tuning and reinforcement learning from human feedback (RLHF) to align the instruction-tuned model with responsible behaviors
- Conducted robust evaluations including manual red-teaming, automated adversarial testing, and assessments of model capabilities for dangerous activities to understand and reduce the risk profile for Gemma models
Overall, Gemma represents a significant step forward in the development of LLMs, and its impressive performance on a range of NLP tasks has made it a valuable tool for researchers and developers alike.
We’re excited to share an overview of our Gemma 7B performance based on ArtificialAnalysis.ai’s recent inference benchmark. Let’s dive in.
Gemma 7B on Groq has set a new record in LLM inference speed. Artificial Analysis has independently benchmarked Groq as achieving 814 tokens per second, the highest throughput Artificial Analysis has benchmarked thus far. For users prioritizing speed and cost, the Gemma 7B model on Groq's API presents a compelling option.
Micah Hill-Smith, Co-creator, ArtificialAnalysis.ai REPOST
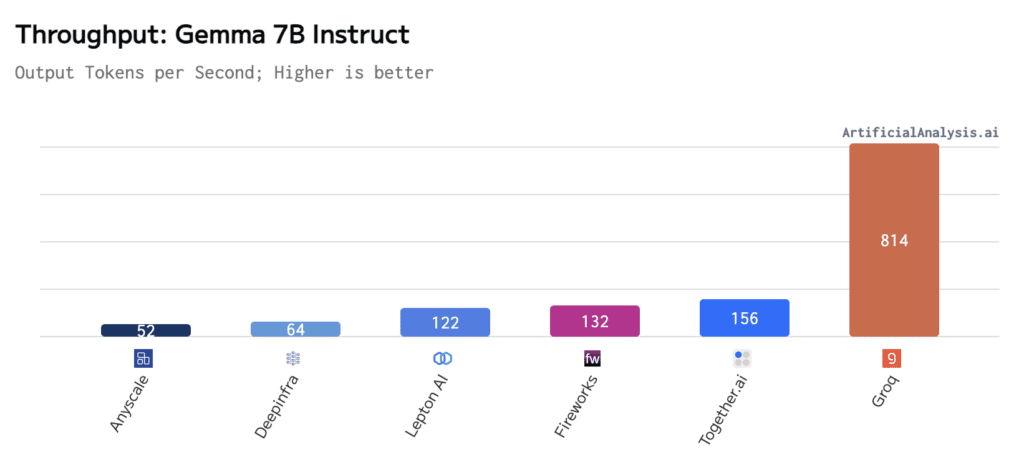
Throughput
As mentioned already, Gemma 7B runs at ~814 tokens per second on the Groq LPU Inference Engine. This is anywhere from 5-15x faster than other measured API providers.
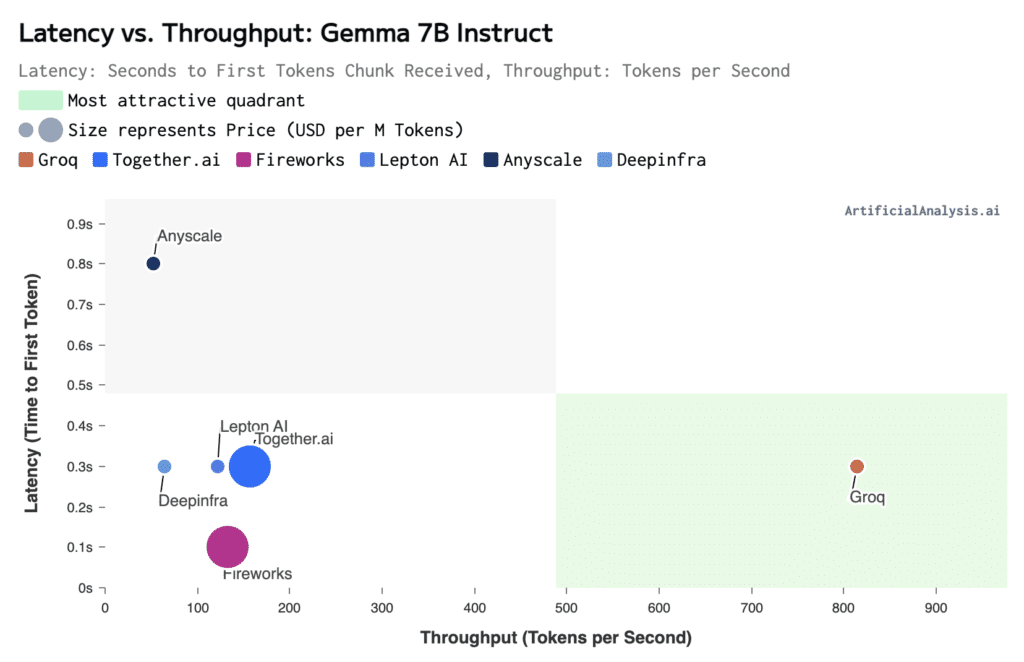
Latency vs. Throughput
For latency, defined as time to first token of tokens received, in seconds, after API request is sent compared to throughput, Groq offers ~814 tokens per second in just 0.3 seconds.
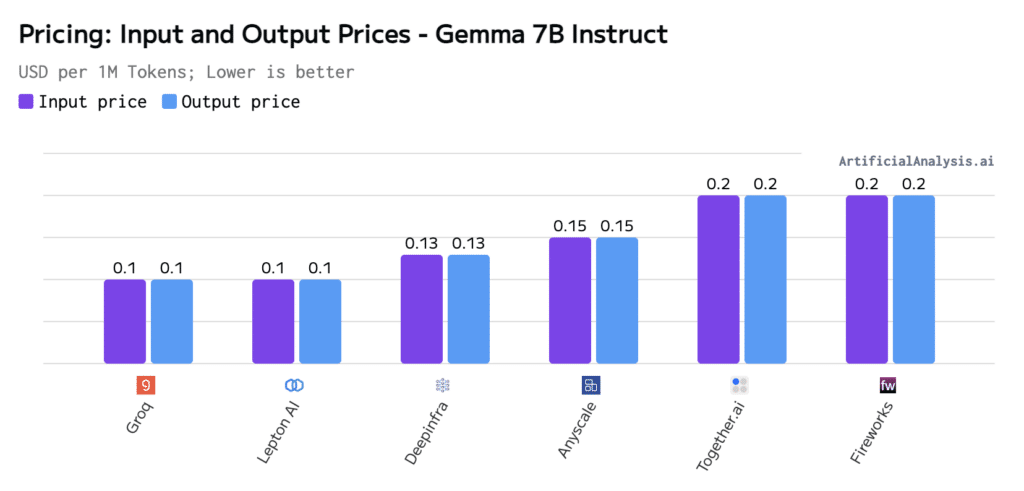
Pricing
Price defined per token included in the request/message sent to the API, represented as USD per million tokens. Groq offers Gemma 7B at an input/output price of $0.10/$0.10.
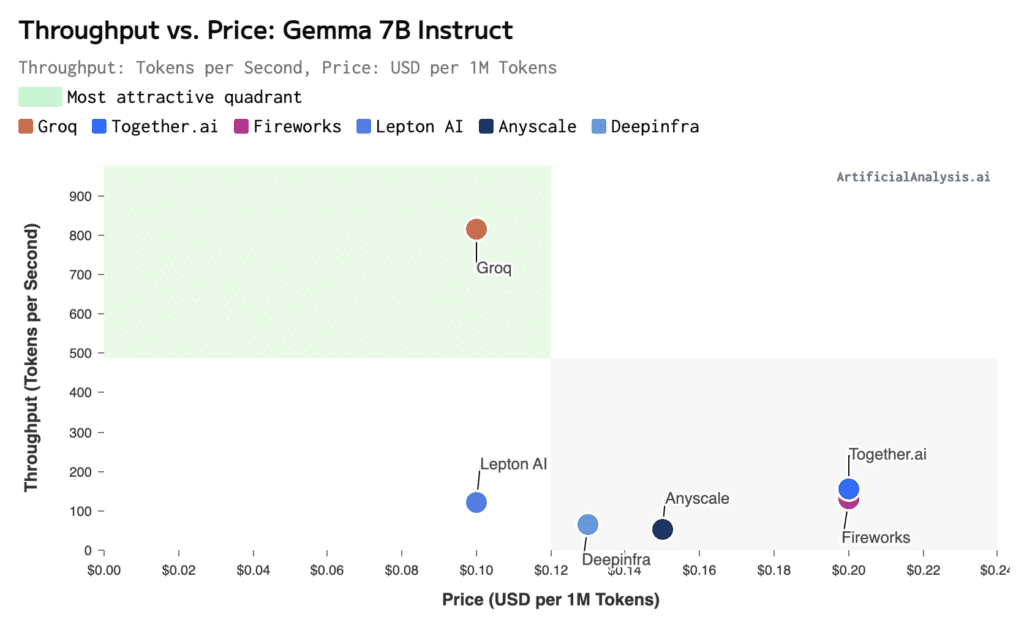
Throughput vs. Price
For throughput, defined as “tokens per second received while the model is generating tokens,” versus price, Groq offers the most attractive results at ~814 tokens per second at a price of just $0.10 USD per one million tokens.
Interested in leveraging Groq API and our LPU Inference Engine? Check out our GroqCloud™ developer playground or reach out to us about Enterprise Solutions.