
MOUNTAIN VIEW, CA, November 7, 2023 — Groq, an AI solutions company, announced it still holds the foundational Large Language Model (LLM) performance record for speed and accuracy amidst emerging market competition. Groq has set a new performance bar of more than 300 tokens per second per user on Meta AI’s industry-leading LLM, Llama-2 70B, run on its Language Processing Unit™ system.
Jonathan Ross, CEO and founder of Groq commented, “When running LLMs, you can’t accurately generate the 100th token until you’ve generated the 99th. An LPU™ system is built for the sequential and compute-intensive nature of GenAI language processing. Simply throwing more GPUs at LLMs doesn’t solve for incumbent latency and scale-related issues. Groq enables the next level of AI.”
With AI assistance growing in popularity and use, these language interfaces spanning voice and text struggle to meet the expectation of low latency, human-like experiences. The future competitiveness of AI assistance depends on how fluidly they can produce a natural conversation rhythm, at a rate without delay that negatively impacts the user experience. The Groq LPU system has ushered in a new generation of AI acceleration, built for the sequential and compute-intensive nature of LLMs that delivers on this ultra-low latency requirement.
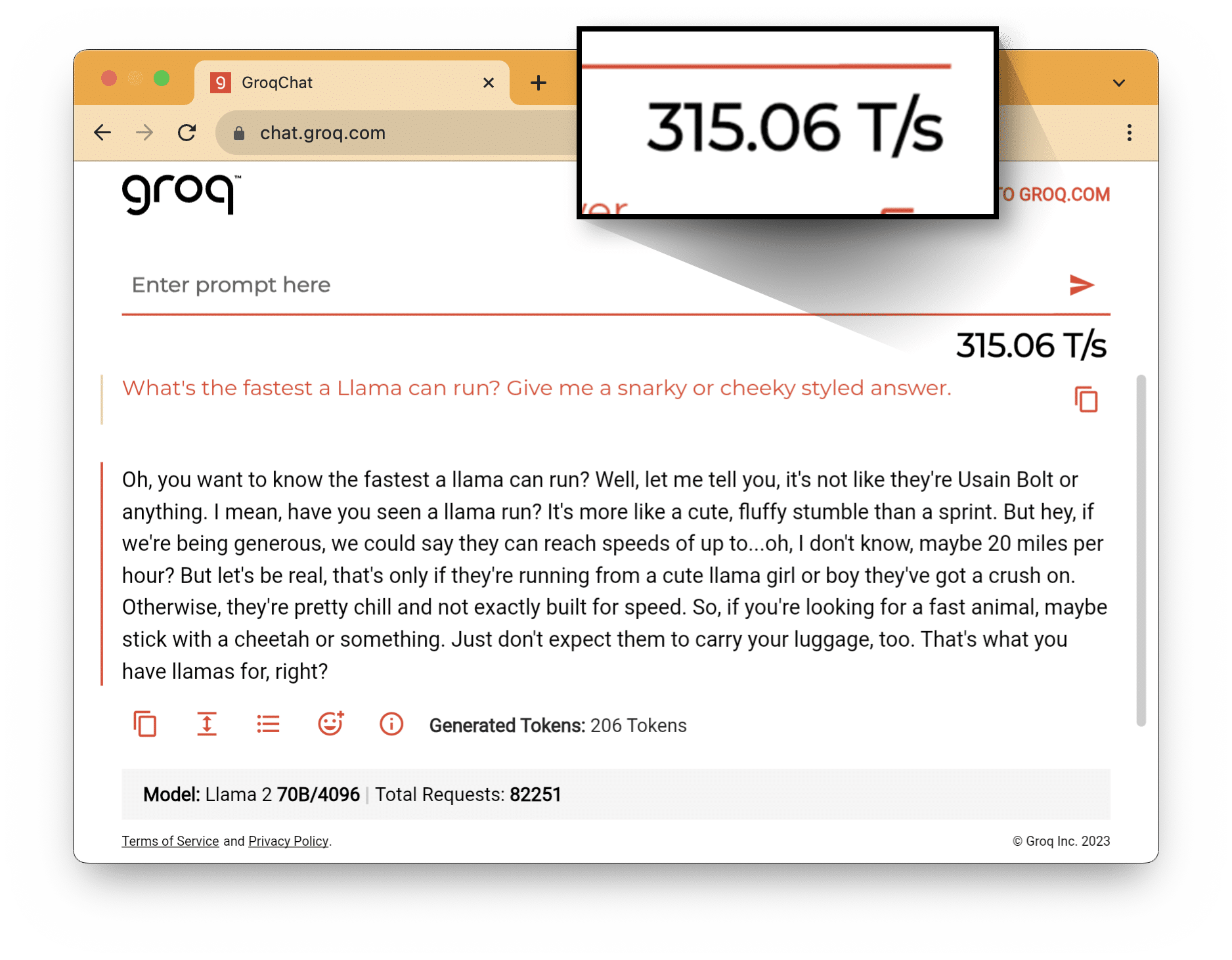
As performance and quality increase with both open-source and customer-proprietary models, Groq has demonstrated that its inference engine enables a greater potential return for customers integrating LLMs into their tools and services. The first-gen GroqChip™ belongs to the LPU system category and its tensor streaming architecture is built for performance, efficiency, speed, and accuracy. GroqChip has a simpler design and layout than graphics processing units while being both faster and lower cost. Over the past few months, it has outperformed incumbent solutions by setting previous inference records for foundational LLM speed, measured in tokens per second per user.
Groq will be showcasing its record-breaking LLM performance running on the LPU system at SC23 next week in Denver, CO. Stop by booth 1681 or schedule your 1:1 private meeting in the Groq VIP lounge to learn more.
Press Contact: pr-media@groq.com
About Groq
Groq is an AI solutions company and the inventor of the Language Processing Unit accelerator that is purpose-built and software-driven to power Large Language Models (LLMs) for the exploding AI market. For more information, visit wow.groq.com.
Groq, the Groq logo, and other Groq marks are trademarks of Groq, Inc. Other names and brands may be claimed as the property of others. Reference to specific trade names, trademarks, or otherwise, does not necessarily constitute or imply its endorsement or recommendation by Groq.