Developer Velocity You Can’t Unsee: Introducing GroqFlow™
Written by:
Groq
The industry needs an automatic, optimizing compiler that targets artificial intelligence (AI)-specific hardware. Today there are many solution stacks that only offer one or two of these three properties–automatic, optimized results, on the right hardware target.
At Groq, we obsess over developer velocity: the idea that you should get from where you are to your goal as fast as possible. We can think of this as Time-to-Results and Time-to-Production. In this context, developer velocity means getting your AI workload from functional to production-optimized in a way that is as fast and–dare we say it–fun, as possible.
The AI space has some amazing productivity tools. Any developer can just install the Huggingface Transformers library and get a novel natural language processing model running on a GPU in minutes. The problem we hear from our customers is that productivity stops before their inference performance goals are met. In other words, developer velocity starts out fast, but velocity for the entire journey, from idea to production can be slow. This is especially true the more you innovate and go off the beaten path of mainstream models.
That’s why we’re introducing GroqFlow™, a simple interface for getting your models running on GroqNode™ servers by adding one line of code.
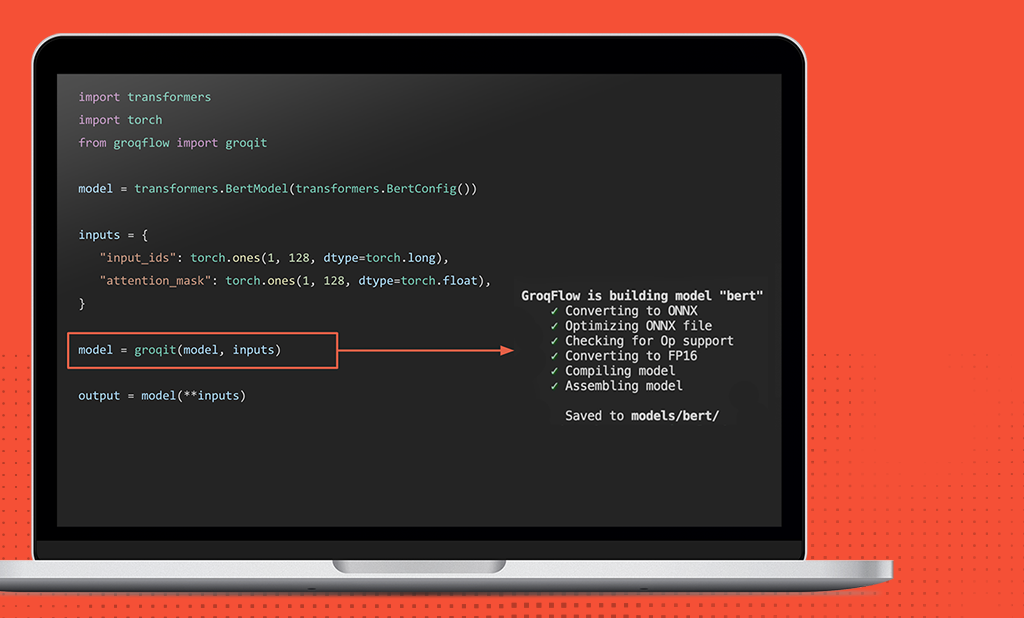
Example program demonstrating how to build and run BERT-Base on a GroqNode system. 1) Instantiate a BERT-Base model from the Huggingface Transformers library, 2) run GroqFlow groqit() function to build the model, and 3) run the model on a GroqNode system the same way you would have run the original Huggingface model.
It is going to be a journey to get GroqFlow ready for the broad spectrum of deep learning frameworks and deployment scenarios that exist today. At Groq though, we believe in sharing rough drafts early and we want you to come on the journey with us. That is why the first release of GroqFlow will be publicly available on GitHub. You’ll be able to see what we’re doing, where we’re going, and more importantly, see a variety of example programs that demonstrate ease-of-use and high developer velocity.
In the early stages of the project, GroqFlow will enable Groq customers to:
Build supported PyTorch models into GroqChip™ programs and run them on GroqNode systems by adding one line of code
Copy examples from Huggingface and get them running on GroqNode servers in under 10 minutes
The goal is to show you our vision for accelerating developer velocity and get your feedback as we begin our GroqFlow journey. So far, the reactions from customer previews of GroqFlow have been electric. We’ve heard things like:
“This is glorious. We need this as soon as possible.” – Science and engineering research customer
“This will make it much faster to get models up and running.” – Cybersecurity customer
We can’t wait to share this tool with you too, and show you developer velocity you can’t unsee. If you’re interested in a hands-on workshop with GroqFlow development on a GroqNode server, please contact info@groq.com.
Blog Contributors: Jeremy Fowers, Victoria Godsoe,Daniel Holanda Noronha, and Ramakrishnan Sivakumar
Never miss a Groq update! Sign up below for our latest news.
This site uses cookies to operate our website and analyze website traffic. Read MoreAcceptReject
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.
The latest Groq news. Delivered to your inbox.
The latest Groq Developer news. Delivered to your inbox.