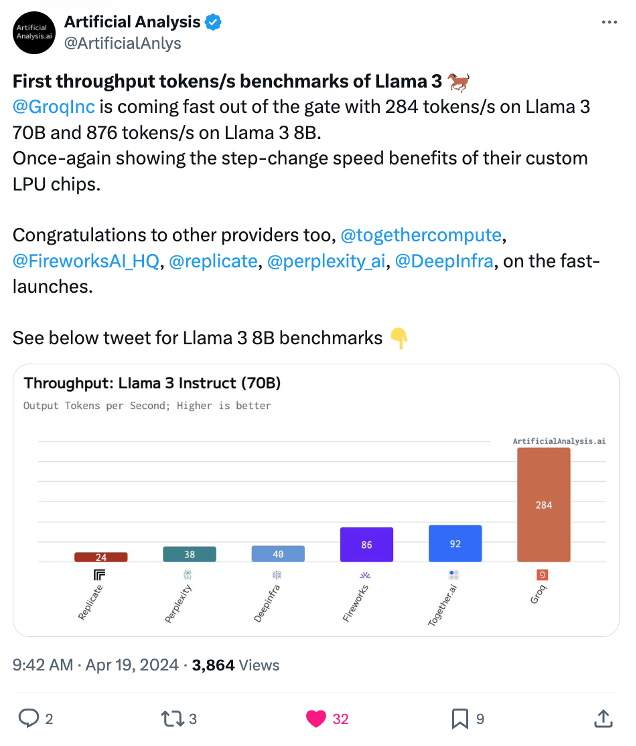
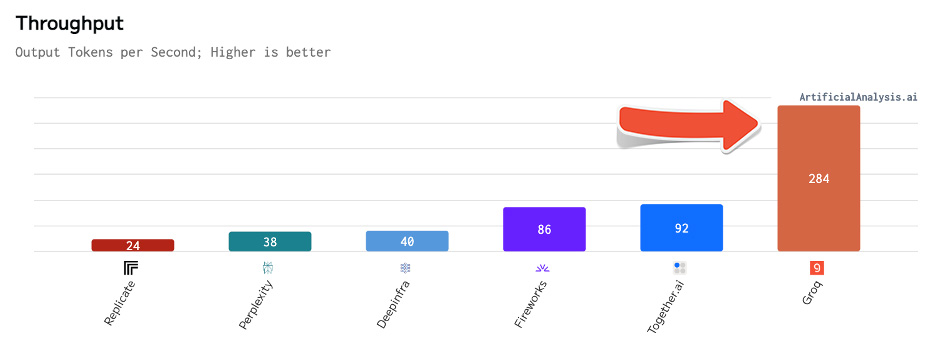
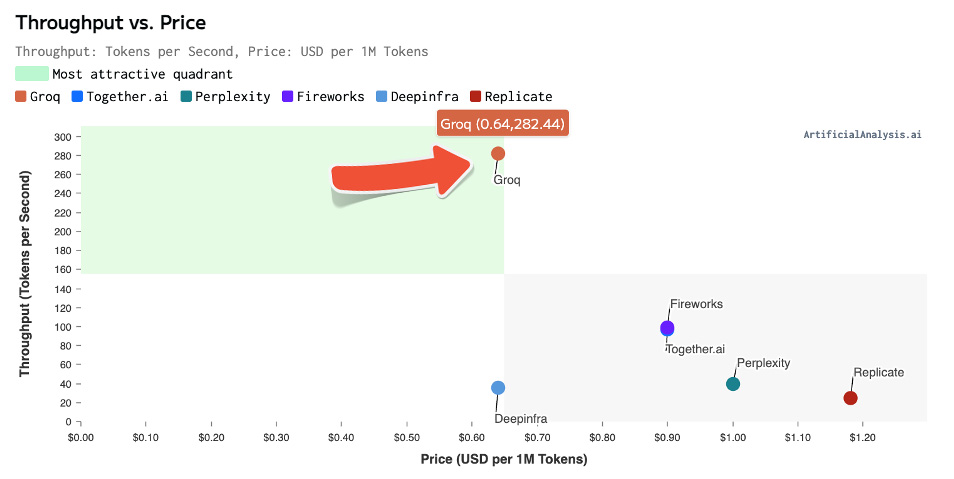
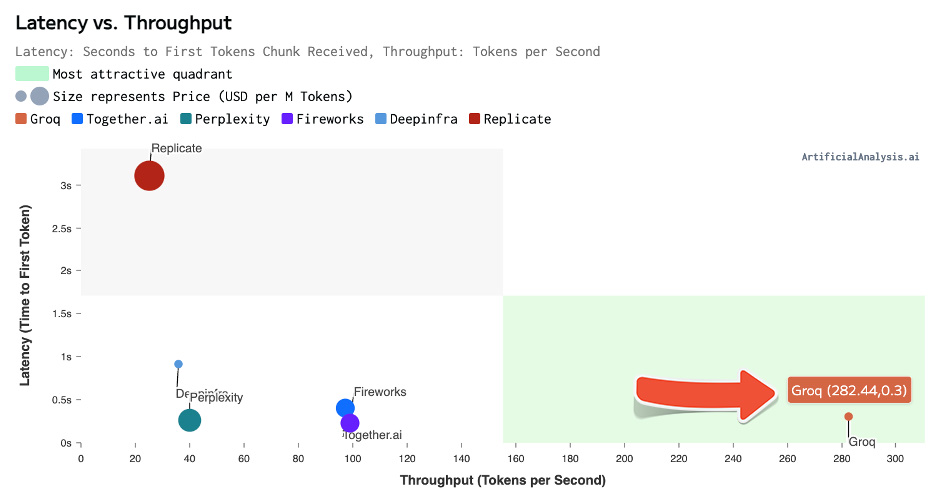
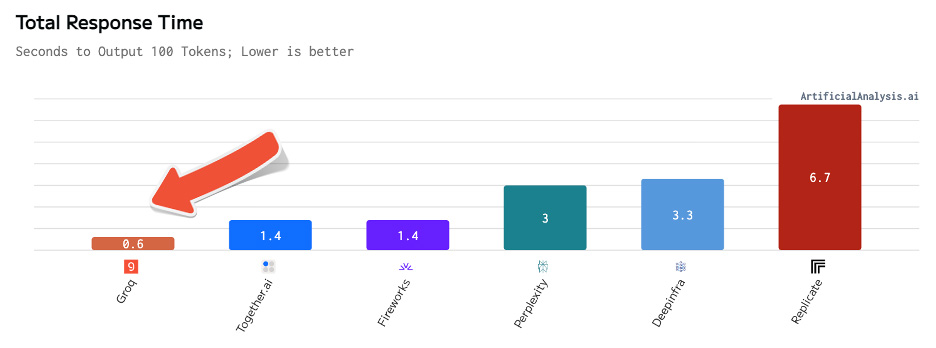
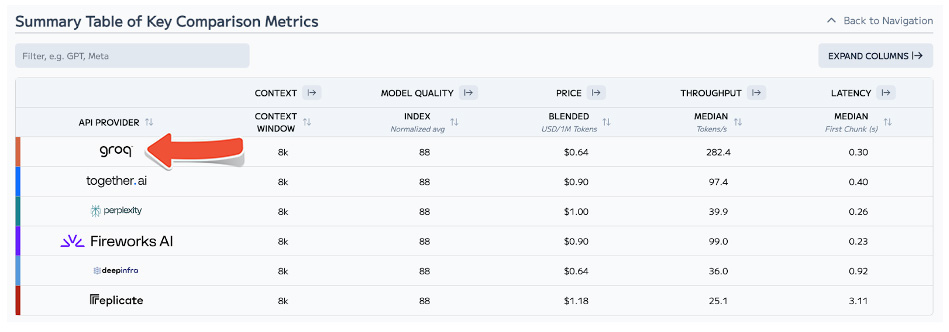
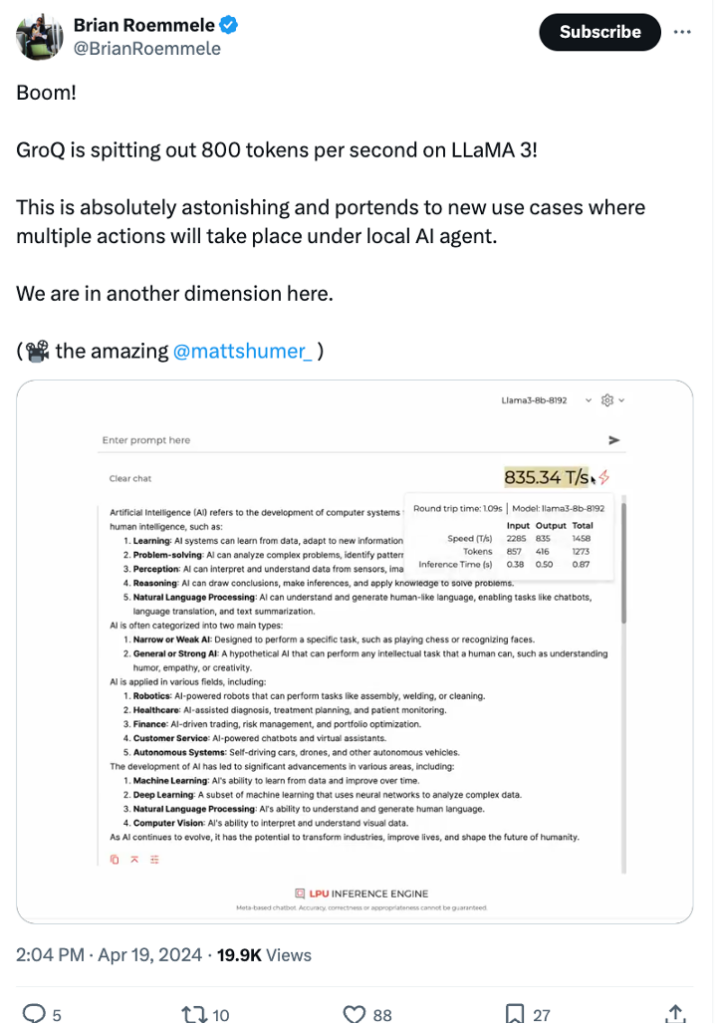
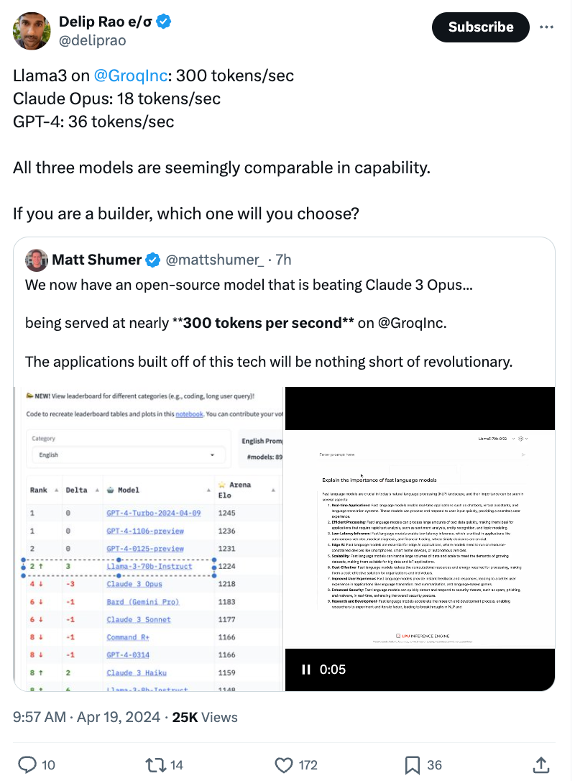
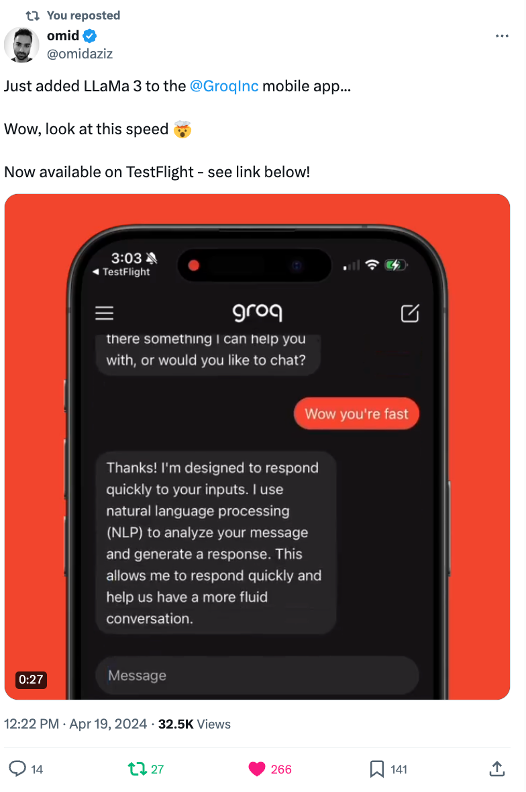
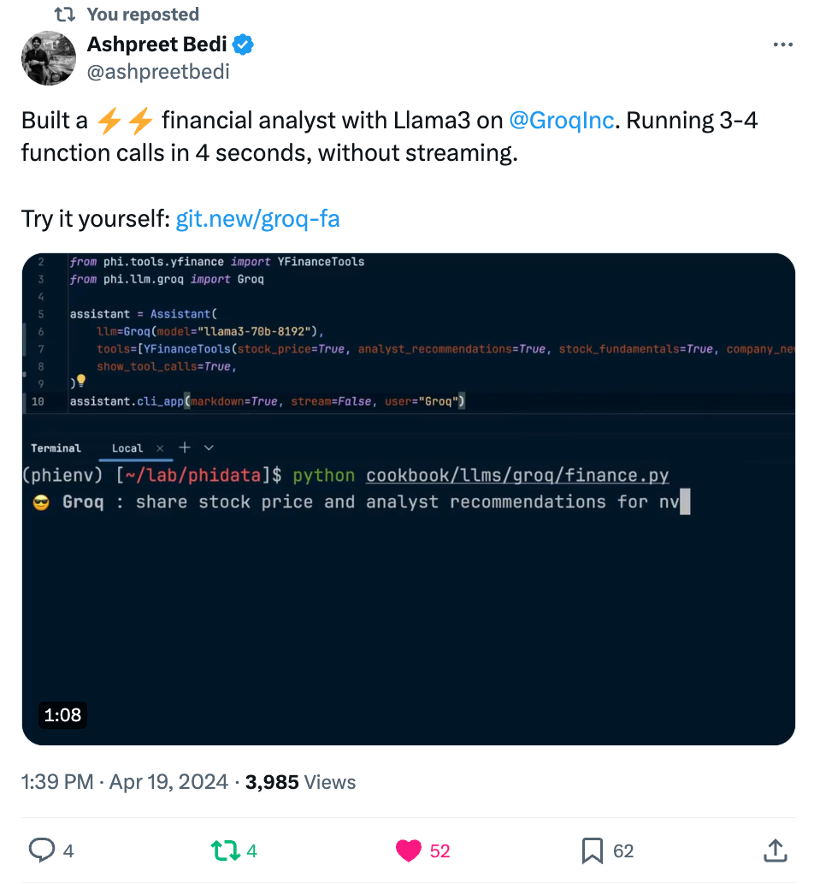
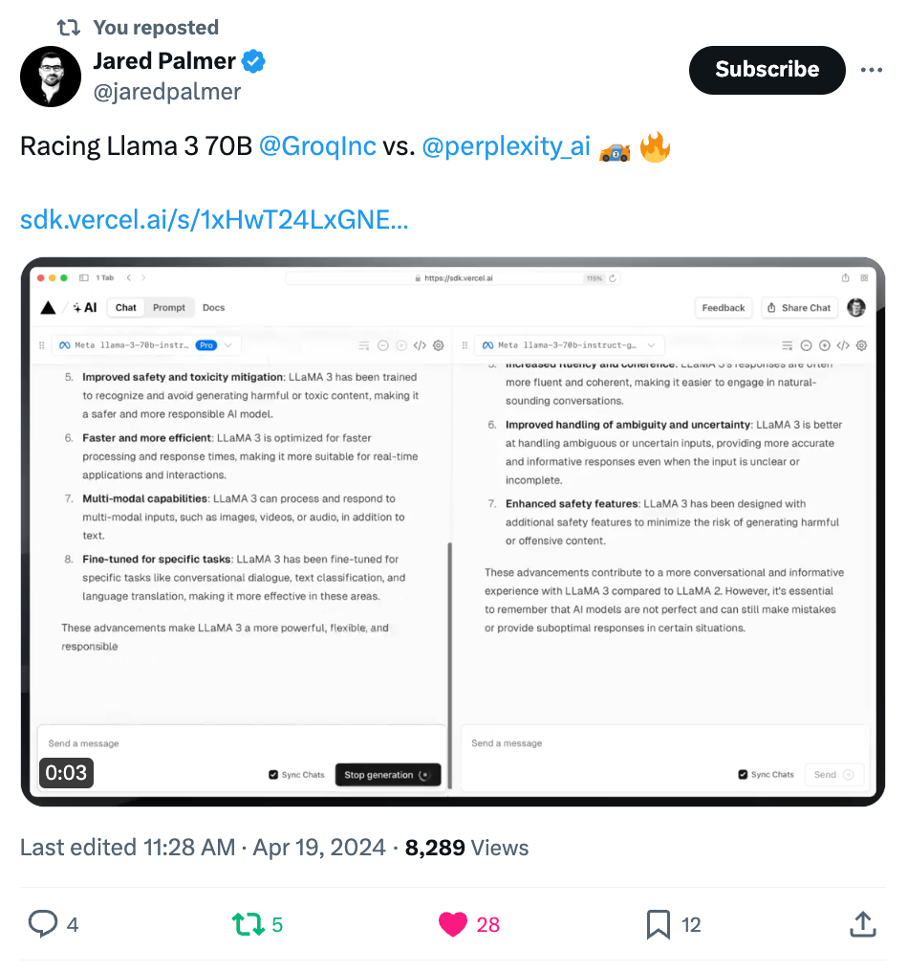
Artificial Analysis has independently benchmarked Groq as achieving a throughput of 877 tokens/s on Llama 3 8B and 284 tokens/s on Llama 3 70B, the highest of any provider by over 2X. Groq's offer is also cost competitive with both models priced at or below other providers. Combined with Llama 3's impressive quality, Groq's offer is compelling for a broad range of use-cases including emerging use-cases which demand a high number of interactions with LLMs such as AI agents.