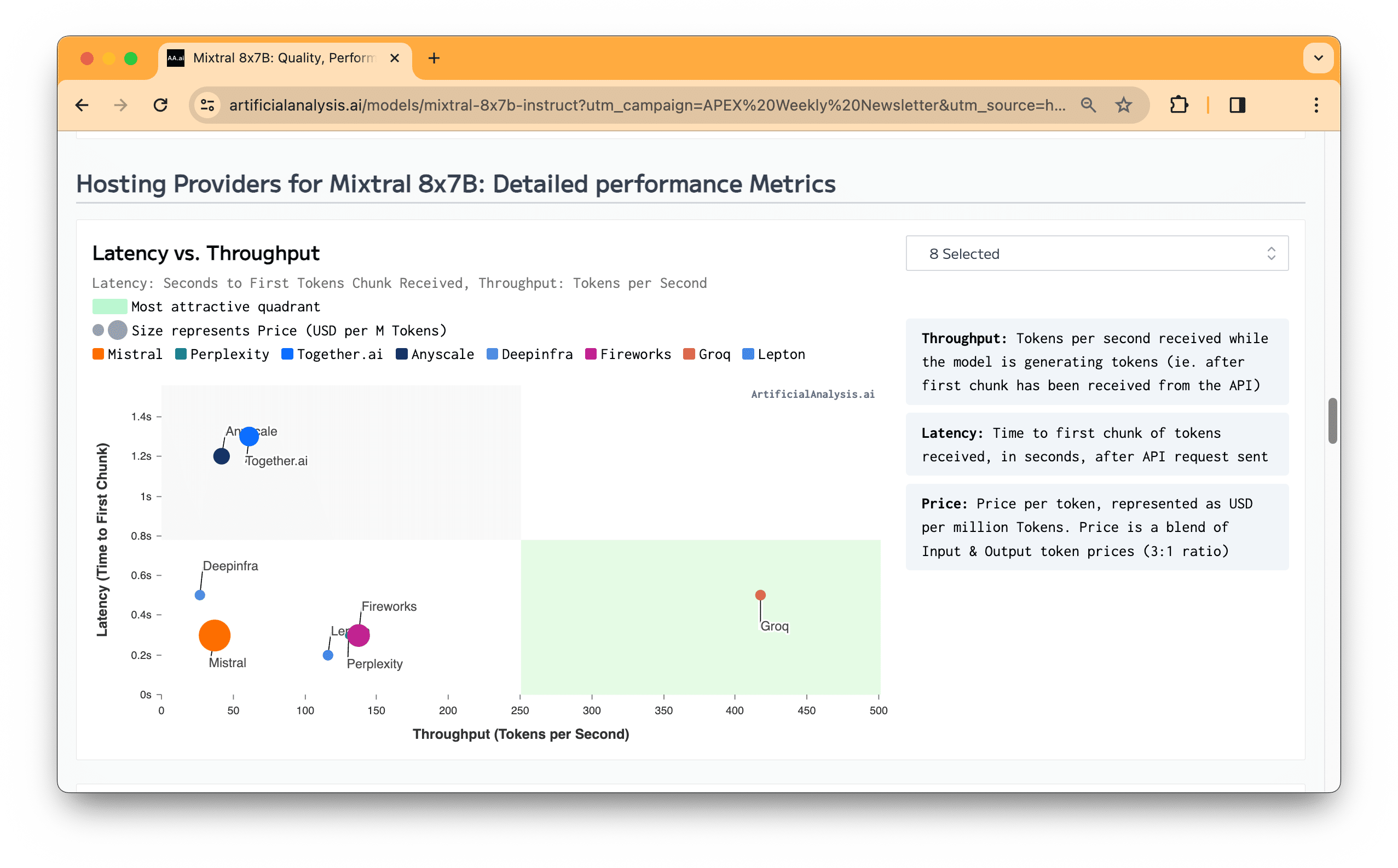
Enterprise Access
GroqCloud™ provides the world's fastest AI inference for LLMs at scale
Do you need the fastest inference at data center scale?
We have multiple tiered solutions to suit your commercial projects via our GroqCloud API.
If you need any of the following listed below we should chat.
Do you need:
- Custom rate limits
- Fine-tuned models
- Custom SLAs
- Dedicated support
Let’s talk to ensure we can provide the right solution for your needs. Please fill out our short form to the right and a Groqster will reach out shortly to discuss your project needs.
Developer access can be obtained completely self-serve through GroqCloud. There you can obtain your API key and access our documentation as well as our terms and conditions on our developer Console. You can chat directly with the Groq team about your needs, feature requests, and more by joining our Discord community.
If you are currently using the OpenAI API, you just need three things to convert over to Groq:
- Groq API key
- Endpoint
- Model
Price
Other models, such as Mistral and CodeLlama, are available for specific customer requests. Send us your inquiries here.
| Model | Current Speed | Price |
|---|---|---|
| Llama 3 70B (8K Context Length) | ~330 tokens/s | $0.59/$0.79 (per 1M Tokens, input/output) |
| Mixtral 8x7B SMoE (32K Context Length) | ~575 tokens/s | $0.24/$0.24 (per 1M Tokens, input/output) |
| Llama 3 8B (8K Context Length) | ~1250 tokens/s | $0.05/$0.08 (per 1M Tokens, input/output) |
| Gemma 7B (8K Context Length) | ~950 tokens/s | $0.07/$0.07 (per 1M Tokens, input/output) |
| Whisper Large V3 | ~210x speed factor | $0.03 /hour transcribed |
| Gemma 2 9B (8K Context Length) | ~500 tokens/s | $0.20/$0.20 (per 1M Tokens, input/output) |
Fastest Inference, Period.